Pythonの動画ダウンロードライブラリyt-dlpを使って複数の動画をダウンロードする際、単純にForループで順番に処理すると時間がかかってしまう。 例えば、次のコードは複数のURLから動画をダウンロードするが、1つずつ順番に処理するため、全体の時間が長くなってしまう。
import yt_dlp
urls = [
"https://www.youtube.com/watch?v=...",
"https://www.youtube.com/watch?v=...",
"https://www.youtube.com/watch?v=...",
...
]
with yt_dlp.YoutubeDL(get_options(file_path)) as ydl:
for url in urls:
ydl.download([url])動画を1つずつ順番にダウンロードするのではなく、並行処理にすることによって全体の時間を短縮したい。
GILとタスクの性質
!注意! Python 3.13以降では、実験的にGILを無効化したバージョンが提供されており、今後GILと並行処理をめぐる状況は大きく変わる可能性がある。
Pythonの並行処理を理解する上で避けて通れないのが、GIL(Global Interpreter Lock) の存在だ。
GILは、Pythonのバイトコードを一度に1つのスレッドでしか実行できないようにするロック機構である。GILの存在により、ある瞬間にPythonのコードを実行できるのは常に1つのスレッドだけに限られる。
GILの挙動を理解するため、タスクの性質を次の2つに分類する。
- I/Oバウンド: ファイルの読み書きやネットワーク通信など、I/Oの待ち時間がボトルネックになるタスク(動画のダウンロードはこちらに該当する)。
- CPUバウンド: 複雑な計算など、CPUの処理能力がボトルネックになるタスク。
I/O待機中にはGILが解放されるため、その間に別のI/O操作を進めることができる。したがって、I/Oバウンドなタスクは、複数スレッドへの分散が効果的だ。
一方、CPUバウンドなタスクでは、GILが効いてしまい、複数スレッドを使っても同時にPythonコードを実行できない。そのため、GILによるロックを回避するには複数プロセスを立ち上げる必要がある。つまり、CPUバウンドなタスクは、複数プロセスへの分散が効果的だ。
並行処理アプローチ
GILの特性とタスクの性質を踏まえると、Pythonの並行処理には複数のアプローチがある。どのアプローチを選ぶべきか、以下のフローチャートを参考に判断できる。
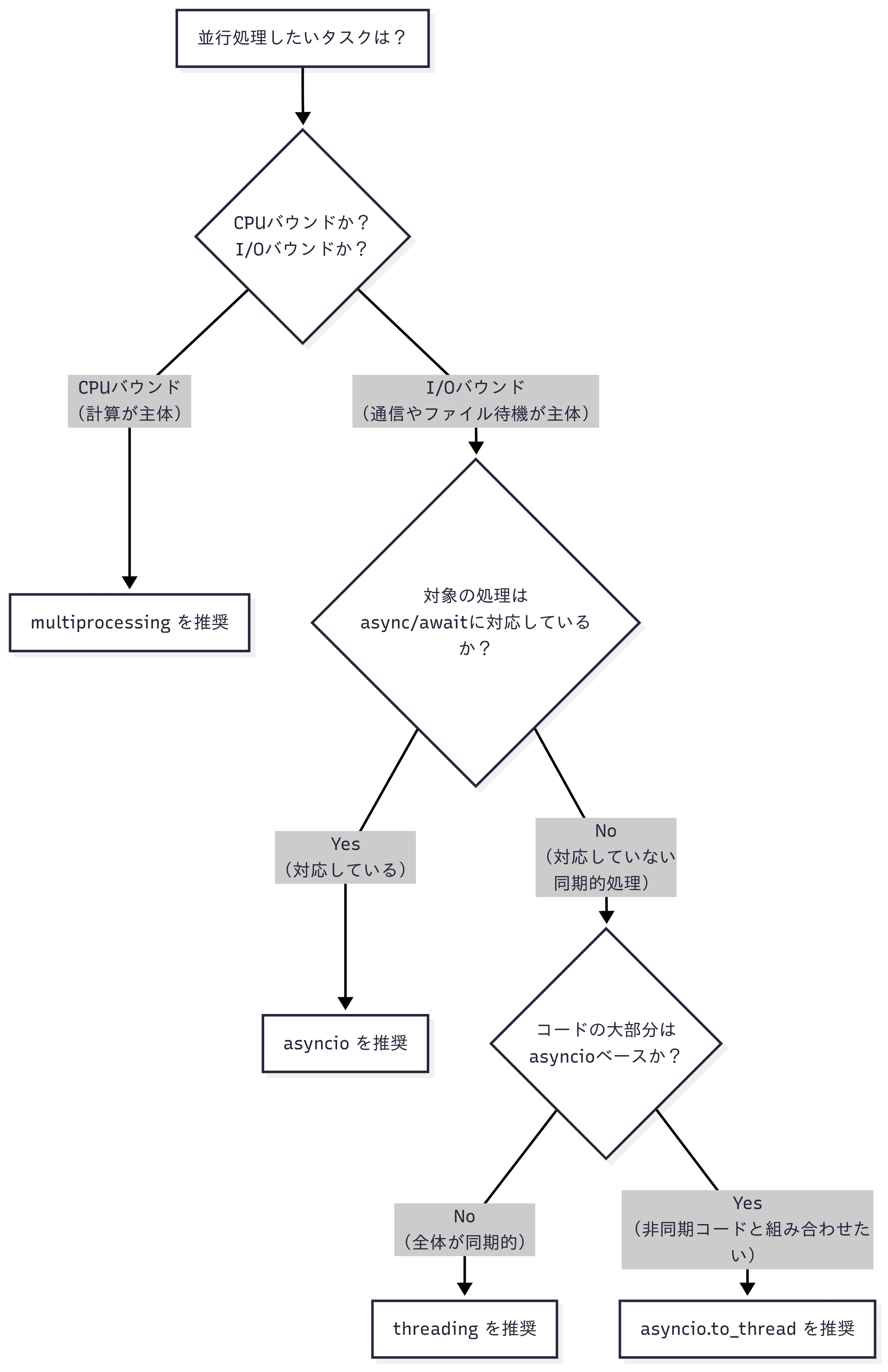
1. multiprocessing: CPUバウンドタスク向け
multiprocessingは、複数のプロセスを立ち上げ、各プロセスで独立してPythonコードを実行するライブラリだ。CPUバウンドなタスクに効果的だが、プロセス間の通信にオーバーヘッドがあるため、I/Oバウンドなタスクにはあまり向いていない。
2. threading: I/Oバウンドタスク向け
threadingは、スレッドを使って並行処理を実現するライブラリだ。I/O待機中にGILが解放され、他のスレッドが処理を進められるため、I/Oバウンドなタスクに非常に効果的だ。ただし、前述の通りGILの存在により、CPUバウンドなタスクには向いていない。
multiprocessingとthreadingには、より高水準なAPIであるconcurrent.futuresモジュールが存在し、こちらを使うと並行処理をより簡単に実装できる。
3. asyncio: I/Oバウンドタスク向けの現代的な方法
asyncioは、Pythonの標準ライブラリで提供される非同期I/Oフレームワークだ。
単一スレッド内のイベントループという仕組みを使い、awaitキーワードでI/O処理の完了を非同期に待ちながら、その間に他の処理を進めることができる。スレッドと同様にI/Oバウンドなタスクに非常に効果的で、threadingよりもさらに軽量に多くの処理を扱える場合がある。
ただし、asyncioに対応した関数でなければ、この方法で並行処理を行うことはできない。yt-dlpはasyncioに対応していないため、そのままawaitを使ってもイベントループがブロックされてしまい、並行処理の効果が得られず、同期的なコードと同じ結果になる。
このような場合はasyncio.to_threadを使うことで、同期的な関数を別スレッドで実行し、その完了を非同期に待つことができる。これにより、asyncioのイベントループをブロックすることなく、同期的なI/Oバウンドタスクを並行化できる(この場合、内部でスレッドを生成しているため、実質的にはthreadingと同様の効果が得られる)。
参考資料
ここまでで紹介した概念についてより深く知りたい場合は、以下の資料が非常に参考になる。
GILについて:
- Understanding the Python GIL, David Beazley
- threading vs multiprocessing in python, Dave’s Space
asyncioについて:
- PEP492
- Build Your Own Async, David Beazley
yt-dlpを並行化する
それでは、実際のコードでyt-dlpを使った動画ダウンロード処理の並行化を試してみよう。
フローチャートに従うと、まずyt-dlpによる動画ダウンロードはI/Oバウンドなタスクである。
そして、yt-dlpはasyncioには対応していない。
そのため、次のようにyt-dlpのdownloadメソッドを直接awaitしようとしても、処理自体は同期的に実行されてしまい、高速化の効果は得られない。
async def async_download_video_thread(video_id: str, file_path: Path):
with yt_dlp.YoutubeDL(get_options(file_path)) as ydl:
# NG: イベントループがブロックされる
await ydl.download([video_id])実質的に冒頭の同期的なコードと同じで、並行化の効果は得られない。
そこで、フローチャートに従い、threadingの利用を検討する。より簡潔に書けるconcurrent.futuresを使うと、次のようになる。
from concurrent.futures import ThreadPoolExecutor
def download_video_thread(video_ids: list[str], file_path: Path, max_workers: int):
def download(video_id):
with yt_dlp.YoutubeDL(get_options(file_path)) as ydl:
ydl.download([video_id])
with ThreadPoolExecutor(max_workers=max_workers) as executor:
executor.map(download, video_ids)もう一つの方法として、asyncio.to_threadの利用がある。これは、同期的な関数を別スレッドで実行し、その完了を非同期に待つことができる関数だ。
async def async_download_video_thread(video_id: str, file_path: Path):
with yt_dlp.YoutubeDL(get_options(file_path)) as ydl:
# 同期的なdownloadメソッドを別スレッドで実行し、完了を待つ
await asyncio.to_thread(ydl.download, [video_id])この方法はasyncioのイベントループをブロックしないため、他の非同期処理と組み合わせる際に有効だ。内部的にはthreadingと同様、複数のスレッドでダウンロード処理を並行化している。
パフォーマンス比較
ここまで紹介した3つのアプローチと、従来の同期的な方法について、実際に動画ダウンロードのパフォーマンスを比較した。
- タスク: 動画を3回ダウンロード
- 動画:最低画質、音声なし(608KB)
- スレッド数: 3
- Python: 3.13
次の4つのアプローチを試した。
1. sync: 通常の同期処理2. async: asyncioでそのままyt-dlpを呼び出す(実質的に同期処理と同じ)3. thread:concurrent.futuresを使い、複数スレッドでyt-dlpを呼び出す4. async-thread: asyncioでスレッドを利用してyt-dlpを呼び出す
実際のコードはgistに、パフォーマンス比較にはhyperfineを利用している。
結果を次のグラフに示す。
- 同期処理(
sync)では約12秒かかった。 asyncはyt-dlpがasyncioに対応していないため、同期処理と同じ約12秒かかった。- スレッドを使った2つの方法(
thread,async-thread)は、いずれも約6秒という結果になった。- スレッドの利用により、ダウンロード速度が約2倍に向上したことがわかる。
まとめ
yt-dlpのような同期的(ブロッキング)なI/Oバウンドタスクを並行化するには、スレッドを利用する方法が有効だ。
asyncioを主に使う場合は、asyncio.to_threadを利用することで、イベントループをブロックせずに同期処理を別スレッドに委譲できる。これは実質的にthreadingと同様の効果だが、他の非同期処理と組み合わせる際にコードの統一性を保てるという利点がある。
将来yt-dlp自体がasync/awaitに対応すれば、asyncio.to_threadを使わずに、より効率的な非同期処理が実現できるだろう。